Hjem » Nyheder » AI’s to sider: Sådan Supplerer Machine Learning og Generativ AI hinanden
AI's to sider: Sådan supplerer Machine Learning og Generativ AI hinanden
Af Erik David Johnson
Læs Erik David Johnsons første blogindlæg om AI's to sider. Indlægget er det første i en serie af 3 indlæg om AI.
AI (kunstig intelligens) er et område i rivende udvikling, og to af de vigtigste teknologier her er klassisk machine learning (ML) og generativ AI. Men hvad adskiller dem egentlig, og hvordan arbejder de sammen? Lad os se på de centrale forskelle og muligheder.
Hvad er klassisk machine learning?
Klassisk machine learning er en metode, hvor computere lærer at genkende mønstre og lave forudsigelser ud fra strukturerede data, som vi forbereder for dem. Denne data kan være alt fra kundeadfærd til billeder. For eksempel bruges ML til at forudsige kundeloyalitet i det vi kalder churn prediction – altså at forudsige, hvilke kunder måske vil forlade virksomheden.
ML-modellerne trænes ved at “se” masser af eksempler og derefter finde mønstre, de kan genkende i nye data. Men for at fungere kræver klassisk ML, at dataene er organiseret og struktureret, ofte som tal eller kategorier, og den er særligt god til opgaver, hvor resultatet er præcist defineret.
Hvad er Generativ AI?
Generativ AI, der bruger store sprogmodeller som Copilot eller ChatGPT, fungerer anderledes. I stedet for at lede efter mønstre i tal fokuserer den på at forstå og generere menneskeligt sprog. Store sprogmodeller er trænet på enorme mængder tekst fra mange kilder og lærer at forstå sprog, tone og sammenhænge. Det gør dem til generalister inden for sprogforståelse, som kan tilpasses til mange opgaver – alt fra at besvare spørgsmål til at skrive tekst.
Hvor klassisk ML er som en “specialist” inden for specifikke dataopgaver, er generativ AI mere som en “sprogforståelsesekspert”, der kan arbejde med ustrukturerede data, som f.eks. tekst og samtaler.
Kort fortalt
• Klassisk ML: God til mønstre i struktureret data (tal og kategorier) og målrettede forudsigelser.
• Generativ AI: God til sprog og ustruktureret data, som det menneskelige sprog.
• Sammen: Generativ AI kan omsætte sprog til tal, som klassisk ML kan bruge til at skabe mere nuancerede forudsigelser.
Hvordan kan de arbejde sammen?
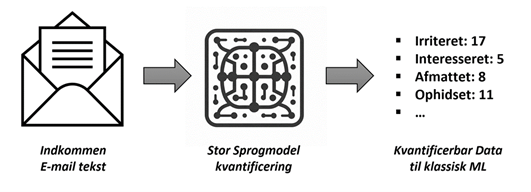
Ved at kombinere klassisk ML med generativ AI åbner vi nye muligheder. Forestil dig churn prediction, hvor en virksomhed gerne vil forudse, om en kunde er på vej væk. Klassisk ML kan bruge data om kundens købsmønstre, men det giver kun et delvist billede. Med generativ AI kan vi også analysere kundens e-mails og vurdere deres tone og følelser – f.eks. om en kunde er irriteret eller tilfreds. Denne sproglige information kan omdannes til tal og bruges som input til ML-modellen. På den måde kan vi få en mere helhedsorienteret analyse, der inddrager både kundens handlinger og følelser.
Med de nye muligheder i generativ AI bliver det vigtigt at overveje, hvordan tekst og tale kan indgå i din datastrategi. Hvor klassisk machine learning primært arbejder med strukturerede data som tal og kategorier, åbner generativ AI op for, at vi nu også kan bruge sproglige data, nemlig hvad andre har sagt og skrevet. Disse data kan give værdifuld indsigt, men for at kunne bruge dem skal de gemmes og organiseres på en måde, så de kan analyseres.
Ved at lagre sproglige data kan en stor sprogmodel hjælpe med at “kvantificere” teksten – altså omsætte sproget til numeriske værdier, som en klassisk ML-model kan bruge til forudsigelser. Hvis en kunde f.eks. udtrykker irritation i en e-mail, kan generativ AI vurdere graden af irritation og omdanne denne information til en værdi, der kan indgå i en churn-prediktionsmodel. Dette kræver, at vi har adgang til kundens sproglige data og kan anvende det i analyserne.
Kort sagt: For at få mest muligt ud af kombinationen mellem klassisk ML og generativ AI bør virksomheder begynde at overveje om de skal indsamle og gemme udvalgte tekst- og taleinteraktioner som en del af deres datastrategi.
Tekst og tale i din nye datastrategi
Om forfatteren
Erik David Johnson, Chief AI Officer
Erik har arbejdet med sprogteknologi i mange år og har for 15 år siden lavet forskning, som peger frem mod den udvikling, vi ser i dag med store sprogmodeller. Hans passion for dette område betyder, at han angriber det fra mange vinkler, hvad enten det er teknisk, etisk, filosofisk eller et hvilket som helst andet aspekt.
Med sine mange års erfaring med at arbejde med machine learning generelt, er Erik begejstret for at formidle til organisationer, virksomheder og den danske regering, hvor han bruges som ekspertvejleder inden for området.